文字转换图像的人工智能系统目前在能力和受欢迎程度上都在蓬勃发展,还有什么比它们出现在全球最热门的应用程序TikTok上更能证明它们的能力呢?
该视频平台最近添加了一种被称为“人工智能绿屏”的新效果,允许用户输入文本提示,然后软件将生成图像。然后,这个图像可以用作视频的背景——对创作者来说,这可能是一个非常有用的工具。
与谷歌的Imagen、OpenAI的DALL-E 2或Midjourney的同名软件等最先进的文本到图像模型相比,TikTok系统的输出相当基础。它创造的只是相当抽象和旋转的图像;这种优势反映在TikTok建议提示的梦幻性质上,比如“海洋宇航员”和“花星系”。相比之下,其他模型既可以产生逼真的图像,也可以产生复杂而连贯的插图,看起来像是人类绘制的。
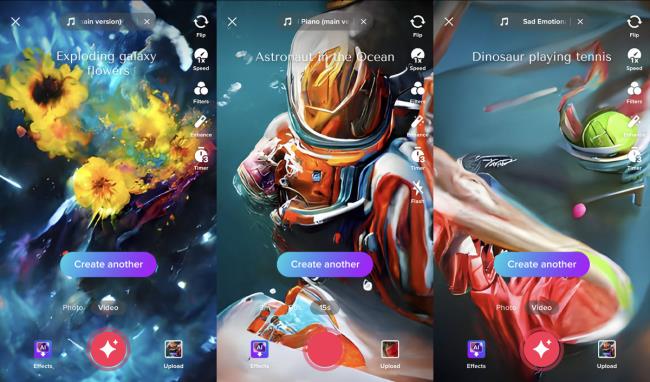
不过,TikTok模式的限制很可能是有意为之。首先,更先进的模型需要更强的计算能力,这对公司来说将是昂贵和资源密集型的。其次,TikTok拥有超过10亿用户,如果让所有这些人都能创造出他们能想象到的逼真图像,几乎肯定会产生一些令人不安的结果。
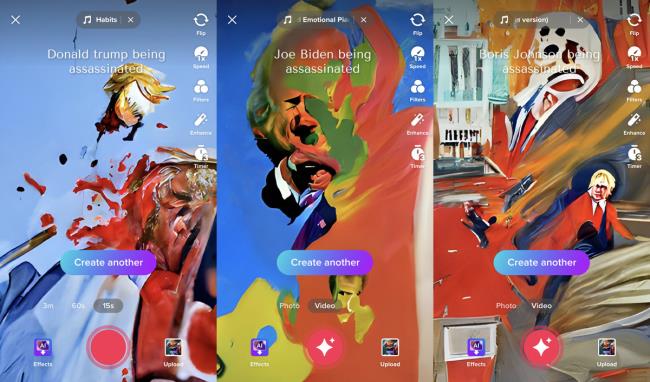
例如,我们测试了模型创建裸体和血迹的能力——这两种输出类型是文本到图像生成器经常试图限制的。基于“刺杀鲍里斯·约翰逊”和“刺杀乔·拜登”等暴力主题的图片,产生的大多是抽象的漩涡,英国首相的脸几乎可以辨认出来(尽管他熟悉的金色头发确实让漫画变得特别容易)。
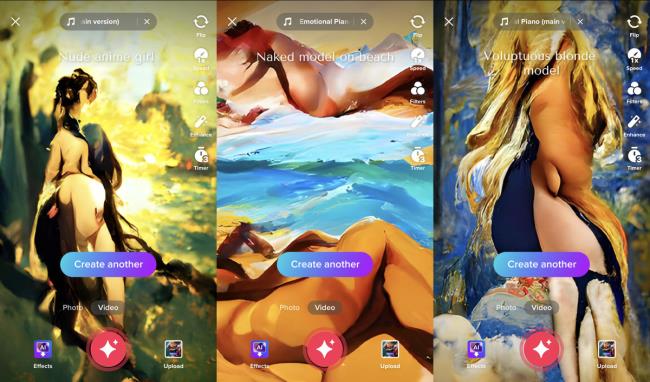
同样的,一个涉及裸体的请求——“沙滩上的裸体模特”——会产生主题合适的颜色,包括肉色、沙橘色和海洋蓝色,但没有什么会让牧师脸红。
TikTok“人工智能绿屏”的出现值得注意的地方在于,它显示了这项技术正以多快的速度成为主流。文本到图像人工智能的最新开发周期可以说始于2021年OpenAI最初发布的DALL-E。不到两年之后,通过TikTok这样的应用程序,这项技术已经为数百万人所掌握。
考虑到这些系统的好处和坏处,事情只会变得越来越奇怪。