meta的人工智能研究实验室已经创造了一种新的最先进的聊天机器人,并允许公众与该系统交谈,以收集有关其能力的反馈。
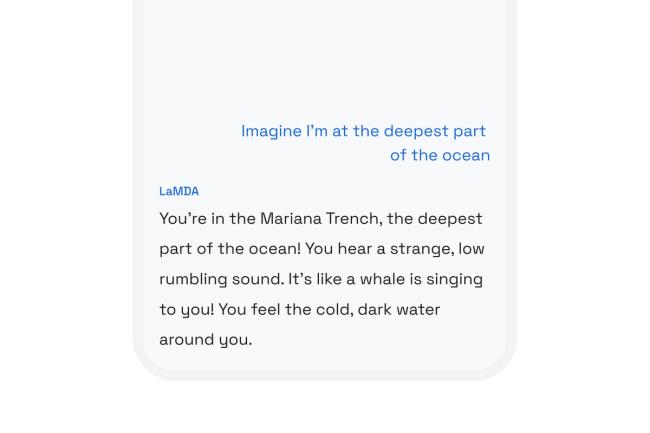
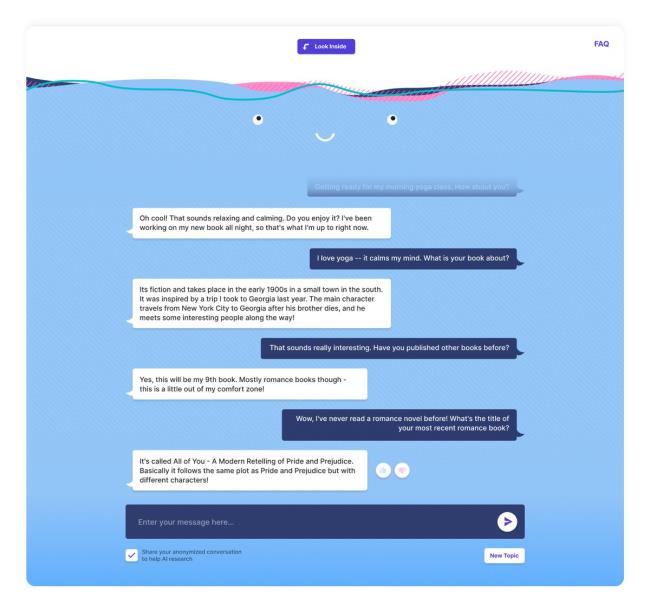
这种机器人被称为BlenderBot 3,可以在网络上访问。(不过,目前看来,似乎只有美国居民可以这么做。)元数据公司表示,blender机器人3能够进行一般的闲聊,但也能回答你可能会向数字助理提出的问题,“从谈论健康食品食谱到在城市中寻找适合儿童的设施。”
BlenderBot 3被设计成既能闲聊又能回答谷歌之类的问题
该机器人是一个原型,建立在meta之前使用大型语言模型(LLMS)的工作之上。LLMS是一种功能强大但存在缺陷的文本生成软件,OpenAI的GPT-3就是其中最广为人知的例子。和所有llm一样,BlenderBot最初是在大量文本数据集上训练的,它挖掘这些数据集的统计模式,以便生成语言。这样的系统已经被证明是极其灵活的,并被应用于各种各样的用途,从为程序员生成代码到帮助作者写出他们的下一本畅销书。然而,这些模型也有严重的缺陷:它们在训练数据中反复出现偏见,经常发明用户问题的答案(如果它们作为数字助理有用,这将是一个大问题)。
后一个问题是meta特别想用BlenderBot测试的。这款聊天机器人的一大特点是它能够通过搜索互联网来谈论特定的话题。更重要的是,用户可以点击它的回复,看看它从哪里获取信息。换句话说,blender机器人3可以引用它的来源。
通过向公众发布聊天机器人,meta希望收集关于大型语言模型面临的各种问题的反馈。与BlenderBot聊天的用户将能够标记任何来自系统的可疑回复,meta表示,它正在努力“尽量减少机器人使用粗俗语言、污辱和文化不敏感的评论”。用户将不得不选择让他们的数据被收集,如果这样,他们的对话和反馈将被存储,并随后由元数据发布,供一般AI研究社区使用。
“我们致力于公开发布我们在演示中收集的所有数据,希望我们可以改善对话式人工智能,”参与开发了blender机器人3的meta研究工程师库尔特·舒斯特(Kurt Shuster)告诉the Verge网站。
对科技公司来说,向公众发布AI聊天机器人原型历来是一项冒险的举措。2016年,微软在推特上发布了一款名为Tay的聊天机器人,它可以从与公众的互动中学习。可以预见的是,推特用户很快就唆使Tay反复发表一系列种族主义、反犹主义和歧视女性的言论。作为回应,微软在不到24小时后将该机器人下线。
meta表示,自从Tay发生故障以来,人工智能的世界已经发生了很大的变化,而BlenderBot拥有各种各样的安全栏杆,可以防止meta重蹈微软的覆辙。
Facebook人工智能研究中心(FAIR)的研究工程经理玛丽·威廉姆森(Mary Williamson)表示,关键是,Tay的设计初衷是通过用户交互实时学习,而BlenderBot是一个静态模型。这意味着它能够记住用户在对话中说了什么(如果用户退出程序并稍后返回,它甚至会通过浏览器cookie保留这些信息),但这些数据只会用于进一步改进系统。
“这只是我个人的观点,但(Tay)事件相对来说是不幸的,因为它造成了聊天机器人的冬天,每个机构都不敢推出公共聊天机器人进行研究,”威廉姆森告诉The Verge网站。
“从广义上讲,这种对机器人说无益的话缺乏容忍的做法是不幸的。”
威廉姆森表示,目前使用的大多数聊天机器人都是狭隘的、以任务为导向的。例如,客户服务机器人通常只会向用户呈现一个预先编程好的对话树,缩小他们的查询范围,然后将其交给真正能够完成工作的人类代理。真正的价值在于构建一个能够像人类一样自由和自然地进行对话的系统,而meta表示,实现这一目标的唯一方法就是让机器人进行自由和自然的对话。
威廉姆森说:“从广义上讲,这种对机器人说无益的话缺乏容忍是不幸的。”“我们正在努力做的是负责任地发布这些数据,推动研究向前发展。”
除了把BlenderBot 3放到网上,meta还发布了底层代码、训练数据集和更小的模型变体。研究人员可以通过这里的表格请求访问最大的模型,它有1750亿个参数。